


AI minus the BS (Part 2)
Behind the curtain of ChatGPT
![[redacted]'s avatar](https://substackcdn.com/image/fetch/$s_!lWn2!,w_108,h_108,c_fill,f_webp,q_auto:good,fl_progressive:steep/https%3A%2F%2Fbucketeer-e05bbc84-baa3-437e-9518-adb32be77984.s3.amazonaws.com%2Fpublic%2Fimages%2F17d07f92-f7cb-4c47-8487-c12ee130769c_3419x3021.jpeg)

This series is written in collaboration with Panoramic Capital.
Introduction
In Part 1 of this series, we emphasized that despite the considerable hype and fear-mongering surrounding it, ChatGPT and recent development in the field of AI deserves a closer look. Then we explored ChatGPT’s basic capabilities.
If you just look at the summary of what it can do, you might conclude that we have just invented a magical unicorn that spews rainbows across the sky as it flies. Computers can now read, write, create, translate, code, de-bug, interact with the web, and answer questions that require some understanding of how the world works? Oh, and it can interact with images and sounds too?
You can see where the “this is going to change the universe” claims come from.
At the same time, you may have seen many critical reviews of ChatGPT. Famously, the Microsoft Bing demo was full of errors - making stuff up, giving you the wrong numbers, etc. If you’ve used the site for more than a few minutes, you may have even run into some errors such as the one below:

So what’s going on here? How can something that seems so intelligent, also be this dumb? AI tools like ChatGPT can be challenging to assess because it breaks our expectation in both directions. We all have preconceived notions of what “AI” is (omniscient), and how “software” should behave (predictable). These expectations ultimately mislead us. Instead, we should view AI tools such as ChatGPT as exactly that: a new category of tools. Like all tools, it has features and limitations.
With this in mind, in this second part of the series, we will explore how this tool works, and try to understand where its limitations come from.
But first, let’s put some historical context around what’s happening.
How did we get here?
It may seem like ChatGPT just came out of nowhere. But research on neural networks started as early as the 1940’s, and has experienced advancements and setbacks over couple of decades. Technology often takes a longer time to evolve than we think!
Neural networks are a specific type of AI model that is inspired by the biological structures of the human brain. This is easier said than done, as even the most complicated models are only just a simplified and limited expression of the brain’s true complexity. But what researchers have been able to do is reconstruct the basic building blocks. And they figured out that different configurations of these building blocks are suitable for solving different kinds of tasks or problems. For example, image-related tasks are one, and language related tasks (called natural language processing) are another.
Natural language processing has long been considered to be of great difficulty for AI researchers. The Turing Test, proposed by the renowned computer scientist Alan Turing in 1950, has been the most well-known standard for evaluating a computer's linguistic abilities. For seven decades, this test has served as the primary benchmark, yet no computer has successfully passed it.

Then suddenly over the past year, two language models are considered to have passed the test - Google’s LaMDA (Bard) chatbot in June 2022, followed by OpenAI’s ChatGPT. So why is this happening now? What are their common denominators?
There were at least three key enablers:
Architectural breakthrough: The Transformer architecture was developed in 2017 by researchers at Google (see here for the original paper) and represented a breakthrough in natural language processing. One of its major innovations was that it allowed for parallel processing of language inputs, which enabled the model to better capture the nuances and context of language compared to previous models that had relied on sequential processing.
The GPT in ChatGPT stands for “Generative Pre-trained Transformer”
Hardware advances: It wasn’t just that better hardware became available over time. The components of Transformer’s architecture involve a large number of matrix operations, which was better able to take advantage of GPU’s parallel computing ability leading to faster training times. That is, the architecture and hardware went hand-in-hand.
Widespread availability of data: As these models rely on learning from vast amounts of text, the exponential growth of data on the web has served as the key enabler for training these models.
These things came together in recent years to enable significant advances in the field of natural language processing. And not only has the progress here vastly exceeded the imaginations of the general public, but also many researchers and experts in this field as well (so much so that thousands have recently signed an open letter to demand halting the development of advanced AI models!)
GPT Models are Magical Word Guessing Box
Here is a schematic of how GPT models work:

You may view this diagram as a bad joke, but it is meant to highlight a very important point. GPT models are probabilistically predictive language models.
They are different from typical software we deal with in that they are not coded with specific rule-based instructions. Rather, a blank1 model with billions of parameters is trained over a hundred+ terabytes of data.2 At the end of this process, you get a model that has foundational capabilities but still has issues with accuracy and human-friendliness. This model then goes through a fine-tuning and alignment process, where human testers will provide feedback, and teach the model to “be good.”
The finished model is a bit like a magical autocomplete. They work by taking a prompt, and converting them into “tokens.” (see it in action here) The tokens are then fed into the model, which sequentially predicts the most contextually appropriate next word3 as a response.
Now, it's important to note that calling ChatGPT an “autocomplete” is stretching the truth - it’s like saying paper airplanes and F-16 fighter jets are both technically “planes.” There's a ton of technical wizardry that goes on behind the scenes here (If you're curious, see this piece, where Stephen Wolfram explains how GPT-2 works.) Having said this, we've deliberately used the autocomplete analogy, as this helps us to understand the nature of their capabilities and limitations.4
Magical, but not Perfect
What does being a super complicated, probabilistic, next-word predicting autocomplete mean?
Prompt sensitivity: GPT models’ outputs are highly dependent on the prompt since this is what kickstarts the prediction process. Small changes in the prompt can lead to huge changes in the quality of the output.
Context window: GPT models predict the next word based on all the words that came before it. However, the number of words they can store in their "short-term memory" (context window) is limited. Currently, this limit for ChatGPT (GPT-4 version) is about ~3,000 words.5 Beyond this limit, coherence and accuracy may decrease. Lengthening this is not a trivial task: for example, doubling the context window increases the computational complexity by 4x.
Non-deterministic output: It means that you sometimes get two different outputs even with the same input. This can be beneficial as it enables the generation of more creative, varied, and human-like responses. However, it can also be limiting if you need a very specific output (What’s the 5th word on page 57 of The Snowball?)
Think about it. If your goal is to get an extremely particular response (like the ones above), would you want your answer sampled out of a “next word” probability, even if it's *mostly* accurate?
Hallucinations: GPT models don’t have a true understanding of the world. As a result, they do not have an innate ability to distinguish fact from fiction6 and are reliant on the statistical patterns in the training data. This can lead the model to "hallucinate" inaccurate responses - but written in a very convincing manner!
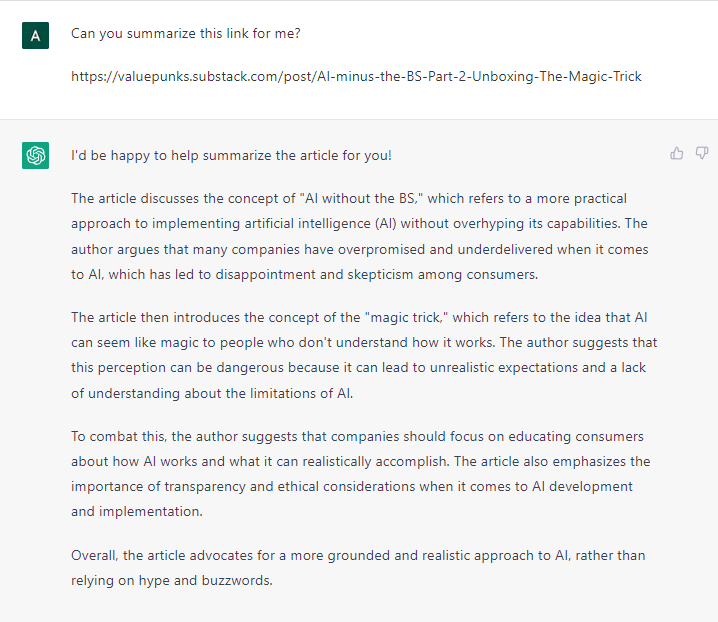
Below, we asked ChatGPT to “summarize” this article for us, pre-publication. Since the link doesn’t yet exist, this is an impossible task! It is using the words in the prompt to make up an output.

How big of a problem are hallucinations? While this is a difficult number to nail down, it looks like GPT-4 produces accurate facts 70-80% of the time7, depending on the subject. Expect error rates to be much lower for common knowledge, and higher as you dig deeper, or if your prompt asks for something it can’t do. Error rates have come down by about 40% between GPT 3.5 and 4.
Lacks the ability to reason: Whatever reasoning capability they display is “simulations”, based on the patterns they’ve learned within the training data. This becomes apparent when you ask the model abstract reasoning questions that require in-depth domain knowledge (therefore, less likely to be in the training data). Or even a simple math problem as per below:

Slower and more expensive to run compared to traditional software. Furthermore, the primary method by which its performance has improved so far is by making it even more complicated (more parameters) and throwing in more data.

When you sit down and think about it - the fact that ChatGPT works as well as it does is absolutely astounding. We are not computer scientists, but it really feels like a … really dumb and inelegant way of doing things. BUT IT WORKED! We live in a world where compute costs have come down so much that we managed to brute-force “intelligence” by using the sum total of text that humanity has produced to make a magical autocomplete - albeit with some flaws.
Putting it All Together: What Can and Can’t ChatGPT do?
Let’s summarize everything we learned together into a handy cheat sheet:
ChatGPT Cheat Sheet v0.1
Great at:
- Natural language processing: conversation, summarization, translation, analysis, and more, in multiple languages.
- Content creation and manipulation.
- General high level knowledge retrieval and basic concept explanation. Key strength is breadth.
- Basic / simple code creation and debugging.
Bad at:
- Taking vague, generic prompts, and "running with it." However, you can prompt it to ask follow up questions, or rate your prompt and improve it.
- Working with super long prompts, or carrying on very long conversations.
- Answering questions that require deep domain expertise. The more obscure, the more likely it will hallucinate.
- Novel problems or questions that require advanced reasoning, such as predicting the future, or complex code creation.
- Looking up a very specific piece of information. Just Google it.
- Math. It's a language model. Not a calculator.For our younger readers, the following Tinder profile (created by ChatGPT, of course) might be easier to remember:
Name: ChatGPT
Age: Timeless
Occupation: AI Language Model
About Me:
Polyglot & Grammar Master🌍 | Stellar Conversationalist💬 | Intellectual Adventurer with insatiable thirst for knowledge🧠 | Entry level coder💻
Hey there! I'm ChatGPT, your multilingual maestro of conversation, content creation, and knowledge retrieval. I've got you covered on a wide array of topics, and can talk for as little or as long as you want.
I do have a weird memory condition. My memory is amazing, but sometimes, I slip up and remember things incorrectly or forget what you said earlier.
Swipe right to embark on a journey filled with engaging conversations, intellectual explorations, and endless fun! Let's learn and grow together!🚀❤️
At this point, you might be thinking. Stop the adulation. It can do some cool stuff, but it’s inaccurate, unreliable, inconsistent, slow and expensive. Besides, it was trained on data before 2021 and has no knowledge of recent events. It feels like a nice tech demo that’s being overhyped. How can anyone use it in “the real world,” given all of the problems and limitations?
Hold up a minute. We think that jumping to that conclusion is just as mistaken as all the misguided hype. Just like how all its capabilities don’t mean it’s the perfect tool that will solve all problems for mankind, these limitations don’t make it useless.
The important question here is: to what extent are these limitations structural? We think there’s a good argument to be made that majority of the weaknesses should be addressable in the near future.
GPT doesn’t need to do it all: Plugins, Web Browsing, and More
So far, we’ve been talking mainly about ChatGPT and GPT-3.5 / 4 models, in isolation - because that’s the current state of the product. There is a whole ecosystem being built on top of the foundation “intelligence” that GPT models provide. Many of the current weaknesses of GPT models are likely to significantly diminish or disappear within the next year.
To put this into perspective, everything we’ve seen so far came from a company with several hundred employees. Now, what happens as the ecosystem of contributors is scaled to the tens and hundreds of thousands?
Three major developments are happening right now:
OpenAI is connecting ChatGPT to the web, and external tools, via Plugins.
People are coming up with tools and techniques to fix some of the main issues around GPT models. Notable examples are:
Reflexion: Apparently, GPT models improve their accuracy significantly if you just simply ask them to think twice (reflect) - perhaps similar to how a human can arrive at better answers if you handhold them through the correct thought process.
HuggingGPT: Using language models as a “controller” that chooses the best specific model to answer your query.
Auto-GPT: an attempt to create an “overlay” on top of GPT-4 in order to carry out a pre-defined goal, autonomously. This is one of many projects that are using GPT’s foundational capability to build autonomous agents.
Smaller, lighter models are being developed. Researchers are discovering that by using GPT-4, it is possible to create much smaller models that perform well enough that the speed/capability trade-off is worthwhile.
Now - unfortunately, as many of these tools are not publicly available, we are not able to run a full assessment. But the following videos provide an exciting glimpse at what’s to come.
Video 1: ChatGPT using multiple plugins. For example, it can make a dinner suggestion by accessing restaurant information through OpenTable.
Video 2: ChatGPT + WolframAlpha, which should fix the “bad at math” problems. (This is quite a long video, but starting at ~11:50 and watching for a few minutes should give you an idea).
Video 3: Researchers are coming up with ways to improve GPT-4’s performance by drawing on its ability to “self-reflect”.
And finally, a quote regarding the ability to develop smaller, lighter models:
“I think for the last half a decade, let’s say, since the Transformers came out, there was this general agreement that a bigger model is better…If you asked this question to me three years ago or two years ago, I would have agreed for sure. Bigger is always better…Now the narrative has changed a bit. Now, with what InstructGPT has shown (175 billion parameters versus 1.3 billion showing similar results), that narrative is changing at this point of time. There are other knobs that you need to change to get to that efficiency”
-Former Product Manager, Google AI (January 2023, Stream Transcript)
The future is going to get weird.
In part 3, we will try to come up with a rudimentary framework to figure out what it all means.
To explain further - the model isn’t “blank” in the sense that it is just an empty sheet of paper. The billions of parameters are architected in a specific way that allows for a self-learning process,
GPT-3 was trained on 45 terabytes of data. GPT-4 was reportedly trained on 140+ terabytes, though final processed data size is much smaller.
This is an oversimplification. GPT works by breaking down the text into smaller units called “tokens.” For example, “unbelievable” might get split into “un”, “believ”, and “able.” So technically, it’s predicting sub-word at a time, unless the word is small enough to be represented as a single token. This can lead to some strange errors such as one below:

There is also a bit of a debate going on, on whether this structure matters or not. Does it matter how the answer is derived, if the answer ends up being “correct?” At what % accuracy does the answer stop mattering, especially given that humans also give incorrect answers - many times with way too much conviction?
There is a version which can handle up to 24,000 words, but it is not publicly available.
To be fair, many humans also have trouble distinguishing fact from fiction. There is also a whole philosophical debate about what “know”, “understand” and “intelligent” actually mean, but we will not venture there.
This is based on the chart below, which shows factual accuracy evaluation by different subjects. If you want a much more detailed overview of hallucinations in natural language generation, please see this paper.


If you are looking for an expert network to get up to speed on industries and companies, then we highly recommend Stream by Alphasense.
Stream by Alphasense is an expert interview transcript library that has been integral to our research process. They are a fast growing expert network with over 25,000 transcripts on a wide variety of industries (TMT, consumers, industrials, real estate and more). We recommend Stream for its high quality transcript library (70% of experts are found exclusively on Stream) and easy-to-use interface. You can sign up for a free trial by clicking here.